1장. 사용자 수에 따른 규모 확장성 - 2편
※ 내용이 많아서 1편과 2편으로 나눴습니다. ※
데이터센터
아래는 두 개의데이터 센터를 이용하는 사례이다.
징애가 없는 상황에서 사용자는 가장 가까운 데이터 센터로 안내되는데, 이 절차를 지리적 라우팅(geoDNS-routing)이라고 부른다.
지리적 라우팅에서의 geoDNS는 사용자의 위치에 따라 도메인 이름을 어떤 IP 주소로 변환할지 결정할 수 있도록 해 주는 DNS 서비스이다.
데이터 센터 중 하나에 심각한 장애가 발생하면 모든 트래픽은 장애가 없는 데이터 센터로 전송된다.
다중 데이터센터 아키텍처를 만들려면 몇 가지 기술적 난제를 해결해야 한다.
- 트래픽 우회
- 올바른 데이터 센터로 트래픽을 보내는 효과적인 방법을 찾아야한다.
- 데이터 통기화(synchronization)
- 데이터 센터마다 별도의 데이터베이스를 사용하고 있는 상황이라면, 장애가 자동으로 복구되어(failover) 트래픽이 다른 데이터베이스로 우회된다 해도, 데이터를 찾을 수가 없다.
- 이런 상황을 막는 보편적 전략은 데이터를 여러 데이터 센터에 걸쳐 다중화 하는 것이다.
- 테스트와 배포
- 여러 데이터 센터를 사용하도록 시스템이 구성된 상황이라면, 여러 위치에서 테스트해 보는 것이 중요하다.
- 자동화된 배포 도구는 모든 데이터 센터에 동일한 서비스가 설치되도록 하는 데 중요한 역할을 한다.
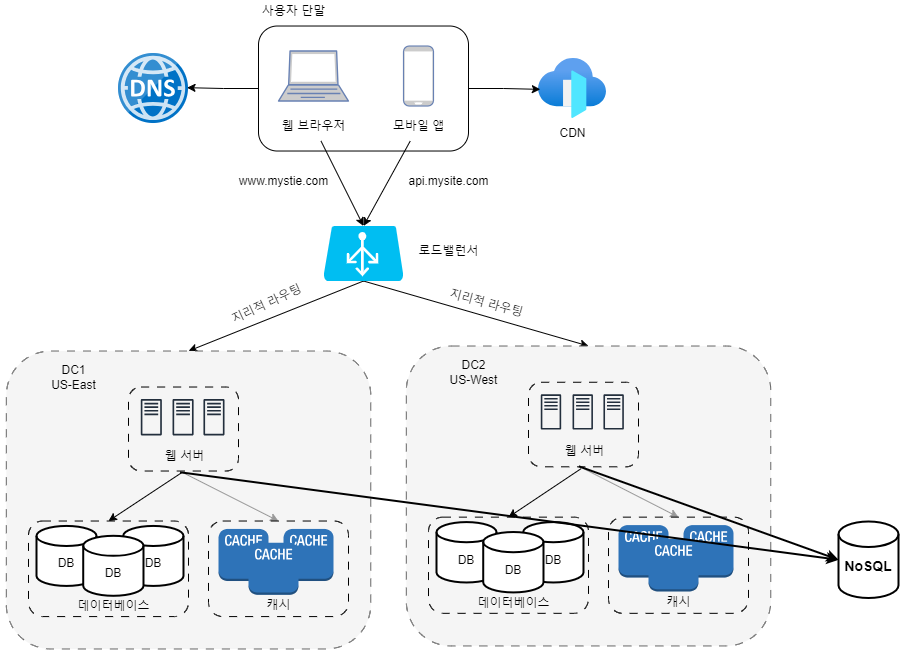
시스템을 더 큰 규모로 확장하기 위해서 시스템의 컴포넌트를 분리하여 각각 독립적으로 확장될 수 있도록 해야한다.
메세지 큐는분산 시스템이 이 문제를 풀기 위해 채용하고 있는 핵심적 전략 방법 중 하나이다.
메세지 큐
메세지 큐는 메세지의 무손실(durability, 메세지 큐에 일단 보관된 메세지는 소비자가 꺼낼 때까지 안전히 보관된다는 특성)을 보장하는, 비동기 통신을 지원하는 컴포넌트.
생산자 또는 발행자라고 불리는 입력 서비스가 메세지를 만들어서 메세지 큐에 발행한다.
큐에는 소비자 혹은 구독자라 불리는 서비스 혹은 서버가 연결되어 있는데, 메세지를 받아 그에 맞는 동작을 수행하는 역할을 한다.
메세지 큐를 이용하면 서비스 간의 결합이 느슨해져서, 규모 확장성이 보장되어야 하는 안정적인 애플리케이션을 구성하기 좋다.
프로세스가 다운이 되어도 생산자는 메세지를 발생할 수 있고, 소비자는 서비스가 가용한 상태가 아니더라도 메세지를 수신할 수 있다.

로그, 메트릭 그리고 자동화
소규모 웹 사이트를 만들 때는 로그나 메트릭, 자동화 같은 것은 꼭 할 필요가 없다.
- 로그
- 에러 로그를 모니터링하는 것은 중요하다.
- 에러 로그는 서버 단위로 모니터링 할 수 도 있지만, 로그를단일 서비스로 모아주는 도구를 활용하면 더 편리하게 검색하고 조회할 수 있다.
- 메트릭
- 메트릭을 잘 수집하면 사업 현황에 관한 유용한 정보를 얻을 수 있다.
- 시스템의 현재 상태를 쉽게 파악할 수 있다.
- 호스트 단위 메트릭:CPU, 메모리, 디스크 I/O에 관한 메트릭이 여기 해당.
- 종합 메트릭: 데이터베이스의 계층의 성능, 캐시 계층의 성능 같은 것이 해당
- 핵심 비즈니스 메트릭: 일별 능동 상용자, 수익, 재방문 같은 것이 해당.
- 자동화
- 시스템이 크고 복잡해지면 생산성을 높이기 위해 자동화 도구를 활용해야 한다.
- 지속적 통합(Continuous integration, CI)을 도와주는 도구를 활용하면 개발자가 만드는 코드가 어떤 검증 절차를 자동으로 거치도록 할 수 있어서 문제를 쉽게 감지할 수 있다.
- 이 외에도 빌드,테스트, 배포 등의 절차를 자동화할 수 있어 생산성을 향상시킬 수 있다.
데이터베이스의 규모 확장
저장할 데이터가 많이지면 데이터베이스에도 부하가 증가한다.
데이터베이스의 규모를 확장하는 두 가지 방법이 있다.
하나는 수직적 규모 확장법이고 다른 하나는 수평적 규모 확장법이다.
수직적 확장
고성능의 자원(CPU, RAM, 디스크 등)을 증설하는 방법이다.
수평적 확장
데이터베이스의 수평적 확장은 샤딩이라고도 부른는데, 더 많은 서버를 추가함으로써 성능을 향상시킬 수 있다.
서버 하드웨어에도 환계가 있으므로 무한 증성할 수 는 없다.
SPOF로 인한 위험성도 크다.
샤딩은 대규모 데이터베이스를 샤드(shard)라고 부르는 작은 단위로 분할하는 기술을 일컫는다.
모든 샤드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터 사이에는 중복이 없다.
사용자 데이터를 어느 샤드에 넣을지는 사용자 ID에 따라 정한다.
user_id % 4를 해시 함수로 사용하여 데이터가 보관되는 샤드를 정한다.
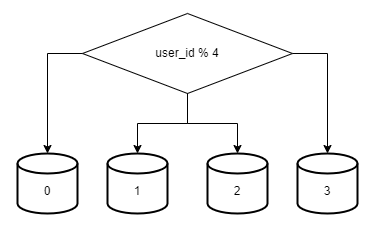
샤딩 전략을 구현할 때 중요한 것은 샤딩 키(sharding key)를 어떻게 정하는냐 하는 것이다.
샤딩 키는 파티션 키(partition key)라고도 부르는데, 데이터가 어떻게 분산될지 정하는 하나의 이상의 칼럼으로 구성된다.
샤딩 키는 user_id 이다.
샤딩 키를 통해 올바른 데이터베이스에 질의를 보내어 데이터 조회나 변경을 처리하므로 효율을 높일 수 있다.
샤딩 키를 정할 때는 데이터를 고르게 분포할 수 있도록 하는게 가장 중요하다.
샤딩을 도입하면 시스템이 복잡해지고 풀어야할 새로운 문제도 생긴다.
- 데이터의 재 샤딩
- 데이터가 많아져서 하나의 샤드로는 감당하기 어려울 때
- 샤드 간 데이터가 균등하지 못하여 어떤 샤드에 할당된 공간 소모가 다른 샤드에 비해 빠르게 진행될 때
- 유명인사 문제
- 핫스팟 키 문제라고도 부른다.
- 특정 샤드에 질의가 집중되어 서버에 과부하가 걸리게 되는 문제
- 조인과 비정규화
- 하나의 데이터베이스를 여러 샤드 서버로 쪼개고 나면, 여러 샤드에 걸쳐 데이터를 조인하기 힘들다.
- 데이터베이스를 비정규화하여 하나의 테이블에서 질의가 수행될 수 있도록 한다.
백만 사용자, 그리고 그 이상
시스템의 규모를 확장하는 것은 지속적이고 반복적인 과정이다.
수백만 사용자 이상을 지원하려면 새로운 전략을 도입해야 하고 지속적으로 시스템을 가다듬어야 한다.