※ 내용을 1편(1, 2단계)과 2편(3, 4단계)으로 나눴습니다. ※
근접성 서비스(proximity service)는 음식점, 호텔, 극장, 박물관 등 현재 위치에서 가까운 시설을 찾는데 이용

1단계: 설계 범위
1.1 기능 요구 사항
세 가지 핵심 기능
- 사용자의 위치와 검색 반경 정보에 매치되는 사업장 목록을 반환
- 사업장 소유주가 사업장 정보를 추가, 삭제, 갱신할 수 있도록 하되, 그 정보가 검색 결과에 실시간으로 반영될 필요는 없다고 가정
- 고객은 사업장의 상세 정보를 살필 수 있어야 한다.
1.2 비기능 요구 사항
- 낮은 응답 지연: 사용자는 주변 사업장을 신속히 검색할 수 있어야 한다.
- 데이터 보호
- 위치 기반 서비스(Location-Based Service, LBS)를 설계할 때는 사용자의 정보 보호 방법을 고려
- GDPR 또는 CCPA와 같은 데이터 사생활 보호 법안을 준수
- 고가용성: 인구 밀집 지역에서 이용자가 집중되는 시간에 트래픽이 급증해도 감당할 수 있어야 한다.
1.3 개략적 규모 추정
- 일간 능동 사용자(Daily Active User, DAU)는 1억명
- 등록된 사업장 수는 2억
- QPS(Query Per Second)는 1억 * 5회 / 10^5 = 5,000
- 사용자는 하루에 5회 검색한다고 가정
- 하루는 24시간 * 60분 * 60초 = 86,400초 를 대략 100,000초로 하여 10^5로 표현
2단계: 개략적 설계
해당 단계에서는 아래 내용을 논의
- API 설계
- 개략적 설계안
- 주변 사업장 검색 알고리즘
- 데이터 모델
2.1 API 설계
1) GET /v1/search/nearby
- 특정 검색 기준에 맞는 사업장 목록을 반환
- API 호출 시, 전달하는 인자
- latitude / 검색할 위도 / decimal(소수)
- longitude / 검색할 경도 / decimal
- radius / 선택적 인자. 생략할 경우 기본값은 5000m / int
- 반환 결과
- { "total" : 10, "businesses" : [ { business object } ]
- business object(사업장을 표현하는 객체)는 검색 결과 페이지에 표시될 모든 정보를 포함
- 사업장 상세 정보 페이지에서는 사업장의 사진, 리뷰, 별점 등의 추가 정보 필요
- 상세 정보 페이지를 클릭하면 또 다른 API를 호출 해서 상세 정보를 가져와야 한다.
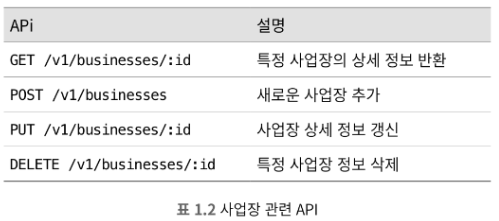
2) 사업장 관련 API
2.2 데이터 모델
해당 절에서는 읽기/쓰기 비율 및 스키마 설계에 대해 알아보자.
1) 읽기/쓰기 비율
읽기 연산이 굉장히 자주 수행, 두 기능의 이용 빈도가 높기 때문
- 주변 사업장 검색
- 사업장 정보 확인
반면 쓰기 연산 실행 빈도는 낮은데, 사업장 정보를 추가하거나 삭제, 편집하는 행위는 빈번하지 않다.
읽기 연산이 압도적인 시스템은 관계형 데이터베이스가 바람직할 수 있다.
2) 데이터 스키마
시스템의 핵심이 되는 테이블은 businees 테이블과 지리적 위치 색인 테이블(geospatial index table)
- business 테이블
- 사업장 상세 정보를 담는다.
- 지리적 위치 색인 테이블
- 위치 정보 관련 연산의 효율성을 높이는데 사용
2.3 개략적 설계
해당 설계는 위치 기반 서비스와 사업장 관련 서비스 두 부분으로 구성
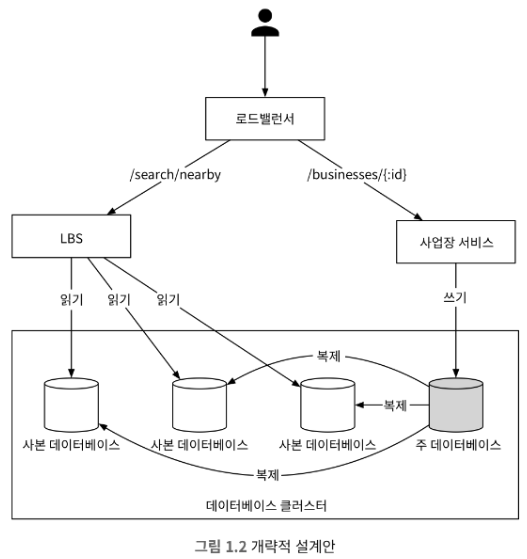
각각의 컴포넌트를 자세하게 살펴본다.
1) 로드밸런서
- 유입 트래픽을 자동으로 여러 서비스에 분산시키는 컴포넌트
- 로드밸런서에 단일 DNS 지점(entry point)를 지정하고, URL 경로를 분석하여 어느 서비스에 트래픽을 전달할지 결정
2) 위치 기반 서비스(LBS)
- 시스템의 핵심 부분으로 , 주어진 위치와 반경 정보를 이용해 주변 사업장을 검색
- 쓰기 요청이 없는, 읽기 요청만 빈번하게 발생하는 서비스
- QPS가 높다. 특히 특정 시간대의 인구밀집 지역일수록 그 경향이 심하다.
- 무상태 서비스이므로 수평적 규모 확장이 쉽다.
3) 사업장 서비스
두 가지의 요청을 주로 처리한다.
- 사업장 소유주가 사업장 정보를 생성, 갱신, 삭제 한다. 쓰기 요청이 기본이다.
- 고객이 사업장 정보를 조회한다. 특정 시간대에 QPS가 높다.
4) 데이터베이스 클러스터
- 주-부(primary-secondary) 데이터베이스 형태로 구성할 수 있다.
- 주 데이터베이스는 쓰기 요청을 처리하며, 부 데이터베이스는 읽기 요청을 처리
- 주 데이터베이스에 기록된 다음에 부 데이터베이스로 복사한다.
5) 사업장 서비스와 LBS의 규모 확장성
- 두 서비스 모두 무상태 서비스로, 특정 시간대에 집중적으로 몰리는 트래픽에는 자동으로 서버를 추가하고 대응
- 유휴 시간 대에는 서버를 삭제하도록 구성
- 시스템을 클라우드에 둔다면 여러 지역, 여러 가용성 구역에 서버를 두어 가용성을 높일 수 있다.
2.4 주변 사업장 검색 알고리즘
많은 회사가 레디스 지오해시(Geohash in Redis)나 PostGIS 확장을 설치한 포스트그레스 테이터베이스를 활용
데이터베이스의 이름 나열보다 지리적 위치 색인이 어떻게 동작하는지 알면 좋다.
크게 보면 색인을 만드는 방법은 아래와 같이 두 종류이다.
(굵은 글자가 업계에서 많이 사용되는 것들.)
- 해시 기반 방안: 균등 격자(even grid), 지오해시(geohash), 카르테시안 계층(cartesian tiers) 등
- 트리 기반 방안: 쿼드트리(quadtree), 구글 S2, R 트리(R-tree) 등
각 색인법의 구현 방법은 서로 다르지만 지도를 작은 영역으로 분할하고 고속 검색이 가능하도록 색인을 만드는 개략적 아이디어는 같다.

1) 2차원 검색
- 주어진 반경으로 그린 원 안에 사업장을 검색하는 방법
- 가장 직관적이지만 지나치게 단순하다는 문제
SELECT business_id, latitude, longitude,
FROM business
WHERE (latitude BETWEEN {:my_lat} - radius AND {:my_lat} + redius)
AND (longitude BETWEEN {:my_long} - radius AND {:my_long} + radius)- 데이터가 2차원적이므로 컬럼별로 가져온 결과도 엄청난 양이다.
- 데이터 집합 1(경도), 데이터 집합 2(위도)의 교집합을 구하는 것은 데이터 양 때문에 비효율적
- 데이터베이스 색인으로는 한 차원의 검색 속도만 개선할 수 있다.

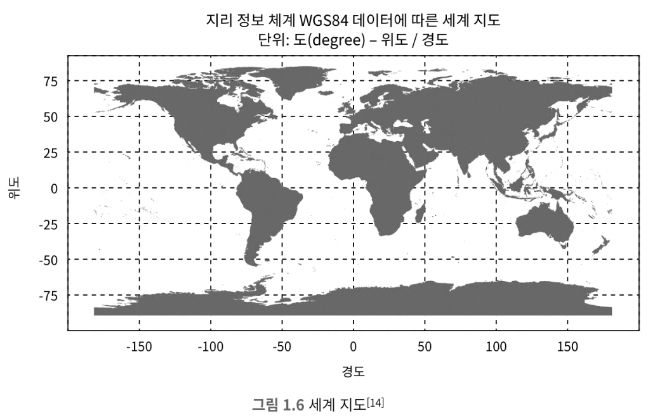
2) 균등 격자
지도를 그림 1.6과 같이 작은 격자 또는 구획으로 나누는 단순한 접근법
특징
- 하나의 격자는 여러 사업장을 담을 수 있고 하나의 사업장은 오직 한 격자 안에만 속한다.
단점
- 격자간의 사업장 분포가 균등하지 않다.
- 뉴욕 다운타운에는 많은 사업장이 있지만, 사막이나 바다 한 가운데는 사업장이 없다.
- 데이터 분표가 균등하지 않다.
- 다른 방안과 달리 격자 식별자 할당에 명확한 체계가 없어 주어진 격자의 인접 격자를 찾기 까다로울 수 있다.
3) 지오해시(Geohash)
2차원의 위도 경도 데이터를 1차원의 문자열로 변환
특징
- 비트를 하나씩 늘려가면서 재귀적으로 세계를 더 작은 격자로 분할
- 지오해시는 통상적으로 base32 표현법을 사용
- 1001 11010 01001 10001 11111 1110 (base32 이진 표기) => 9q9hvu
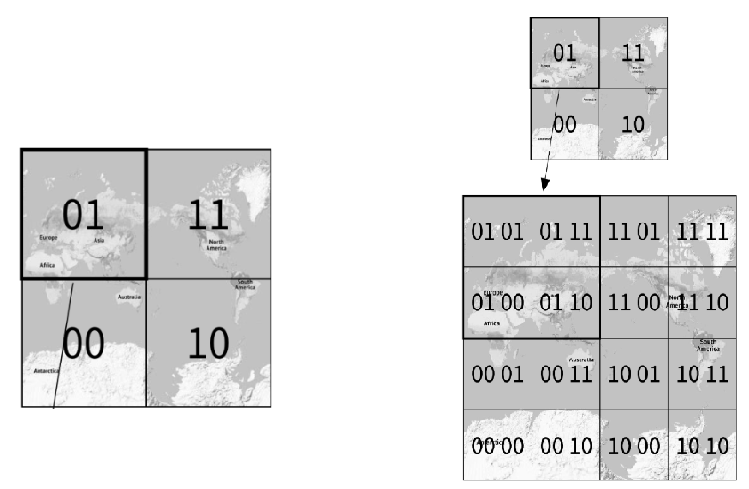
과정
- 전 세계를 자오선과 적도 기준으로 사분면으로 나눈다.
(그림 1.7의 왼쪽과 같다.)- 위도 범위 [-90, 0]은 0에 대응 / 위도 범위 [0, 90]은 1에 대응
- 경도 범위 [-180, 0]은 0에 대응 / 경도 범위 [0, 180]은 1에 대응
- 해당 격자(사분면)를 다시 사분면으로 나눈다.
(그림 1.7의 오른쪽과 같다.)
- 각 격자는 경도와 위도 비트를 앞서 살펴본 순서대로 반복하여 표현
- 원하는 정밀도를 얻을 때까지 반복
지오해시는 12단계 정밀도
- 보통 4에서 6 사이
- 6보다 길어지면 격자가 너무 작아지고
- 4보다 작으면 반대로 격자가 너무 커진다.

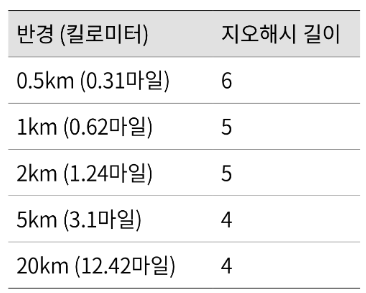
최적 정밀도
- 사용자가 지정한 반격으로 그린 원을 덮는 최소 크기 격자를 만드는 지오해시 길이를 구해야한다.
- 아래 표는 반경과 지오해시 사이의 관계
격자 가장자리 관련 이슈
지오해시는 해시값이 공통 접두어(prefix)가 긴 격자들이 서로 더 가깝게 놓이도록 보장
이슈 1: 아주 가까운 두 위치가 어떤 공통 접두어도 갖지 않는 일이 발생할 수 있다.
- 두 지점이 적도의 다른쪽에 놓이거나, 자오선상의 다른 반대쪽에 놓이는 경우
- 예를 들어, 프랑스 라 호슈 살레의 지오해시 u000로 표현되지만 30km 떨어진 포메홀은 지오해시 ezzz 값을 갖는다.
- 두 지오해시 사이에 어떤 공통 접두어도 없다.
- 접두어 기반 SQL 질의문을 사용하면 주변 모든 사업장을 가져올 수 밖에 없다.
이슈2: 두 지점이 공통 접두어 길이는 길지만 서로 다른 격자에 놓이는 경우
- 해결 방법으로 현재 격자를 비롯한 인접한 모든 격자의 모든 사업장 정보를 가져오는 것
이슈3: 표시할 사업장이 충분하지 않은 경우
- 선택지 1: 사업장이 부족해도 주어진 반경 내 사업장만 반환
- 사용자의 욕구를 만족하는 충분한 수의 사업장 정보를 반환하지 못 한다.
- 선택지 2: 검색 반경을 키운다.
- 지오해시 값의 마지막 비트를 삭제하여 얻은 새 지오해시 값을 사용해 주변 사업장을 검색
- 충분한 사업장이 나올 때까지 반복하여 범위를 확장한다.
아래 부터는 트리 방식
4) 쿼드 트리
- 격자의 내용이 특정 기준을 만족할 때까지 2차원 공간을 재귀적으로 사분면 분할하는데 사용
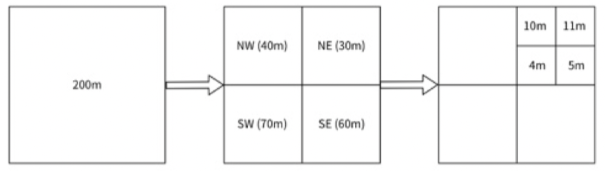
- 쿼드트리를 사용한다는 것은 질의에 답하는 데 사용될 트리 구조를 메모리 안에 만드는 것
- 쿼드트리는 메모리 안에 놓이는 자료 구조일 뿐 데이터베이스가 아니다.

Q. 쿼드 트리를 전부 저장하는데 얼마나 많은 메모리가 필요한가?
=> 어떤 데이터가 쿼드트리에 보관되는지 살펴봐야한다.
말단 노드에 수록되는 데이터

내부 노드에 수록되는 데이터

- 총 메모리 요구량 = 1.71GB로, 부가적인 메모리 요구량을 감안해도 총 메모리 요구량이 꽤 작다
- 쿼드 트리 인덱스가 메모리를 많이 잡아먹지 않으므로 서버 한 대에 충분히 올릴 수 있다.
- 만약 읽기 연산이 많아지면 CPU나 네트워크 대역폭으로 감당하기 어렵기 때문에 분산 시킬 필요가 있다.
Q. 전체 쿼드트리 구축에 소요되는 시간은?
- 200m 개의 사업장 정볼르 인덱싱하는데 쿼드트리 구축에는 몇 분 정도가 소요될 수 있다.
Q. 쿼드트리로 주변 사업장을 검색하려면?
- 메모리에 쿼드트리 인덱스를 구축
- 검색 시점이 포함된 말단 노드를 만날 때까지, 트리의 루트 노드부터 탐색
- 만약 해당 노드에 충분한 사업장이 없으면 확보될 때까지 인접 노드 추가
쿼드트리 운영 시 고려사항
- 새로운 버전의 서버 소프트웨어를 릴리스 할 때는 동시에 너무 많은 서버에 배포하지 않도록 조심
- 200m개 사업장을 갖는 쿼드트리를 구축하는데 몇 분이 소요되기 떄문에 서버 시작 시간이 길어지고 그 동안 서버는 트래픽을 처리할 수 없다,
- 사업장이 추가/삭제 되었을 때 쿼드트리를 갱신하는 문제
- 모든 서버를 한 번에 갱신하는 대신 점진적으로 갱신하는 것.
(짧은 시간 동안이지만 낡은 데이터가 반환될 수 있지만 용인할 수 있다.) - 추가 및 갱신되는 사업장 정보는 다음날 반영된다는 협약을 하면 된다.
- 실시간으로 갱신하는 것도 가능
- 설계가 복잡하지고 여러 스레드가 쿼드트리 자료구조를 동시에 접근하는 경우 락 메커니즘을 사용해야한다.
- 모든 서버를 한 번에 갱신하는 대신 점진적으로 갱신하는 것.
5) 구글 S2
- 지구(sphere)를 힐베트 곡선(Hilbert curve)이라는 공간 채움 곡선(space-filling curve)을 사용하여 1차원 색인화(indexing) 하는 방안
- 힐베트 곡선 상에서 인접한 두 지접은 색인화 이후 1차원 공간 내에서도 인접한 위치에 있다.
- S2는 지오펜스를 구현하는데 지오펜스는 실세계 지리적 영역에 설정한 가상의 경계이다.
- 특정 지점 반경 몇 km 이내와 같이 동적으로 설정
- 스쿨 존이나 동네 경계처럼 이미 존재하는 경계선들을 묶어 설정
- S2가 제공하는 영역 지정 알고리즘이 있다.
- 지오해시처럼 고정된 정밀도가 아니라 셀 크기를 유연하게 조정할 수 있어 반환하는 결과가 더 상세하다.
6) 지오해시 VS 쿼드트리
- 지오해시
- 구현과 사용이 쉽고 트리를 구축할 필요가 없다.
- 색인 갱신이 쉽다. 색인에서 사업장 하나를 삭제하려면 지오해시값과 사업장 식별자가 같은 열 하나를 제거하면 된다.
- 쿼드 트리
- 구현하기가 더 까다롭다. 트리 구축이 필요
- k번째로 가까운 사업장까지의 목록을 구할 수 있다.
=> 검색 반경에 상관없이 내 위치에서 가까운 사업장 k개를 원할 때 사용 - 인구 밀도에 따라 격자 크기를 동적으로 조정할 수 있다.
- 지오해시보다 색인 갱신이 까다롭다.
=> 트리 형태 자료구조로 루트 노드부터 말단 노드까지 트리를 순회해야 한다.
'읽은 책 > [책] 가상 면접 사례로 배우는 대규모 시스템 설계 기초 2권' 카테고리의 다른 글
| 4장. 분산 메세지 큐 - 1 편 (0) | 2024.08.12 |
|---|---|
| 3장. 구글 맵 - 2편 (0) | 2024.08.11 |
| 3장. 구글 맵 - 1편 (0) | 2024.08.01 |
| 2장. 주변 친구 (0) | 2024.07.28 |
| 1장. 근접성 서비스 - 2편 (0) | 2024.07.28 |