순위표란? 특정 토너먼트나 경연에서 누가 선두를 달리고 있는지 보여주기 위해 게임등에서 흔히 사용하는 장치다.
사용자는 과제나 도전을 완료하면 포인트를 받으며, 가장 많은 포인트를 획득한 사람이 순위표의 맨 위에 자리한다.
1단계: 설계 범위
1) 기능 요구사항
- 순위표에 상위 10명의 플레이어를 표시한다.
- 특정 사용자의 순위를 표시한다.
- 어떤 사용자보다 4순위 위와 아래에 있는 사용자를 표시한다.
2) 비기능 요구사항
- 점수 업데이트는 실시간으로 순위표에 반영한다.
- 일반적인 확장성, 가용성 및 안정성 요구사항
3) 개략적 규모 추정
- DAU가 50만 명인 게임의 경우 초당 평균 50명의 사용자가 게임을 플레이한다.
- 사용량이 균등한 경우는 없기 때문에 초당 250명의 사용자를 감당할 수 있어야 한다.
- QPS는 50 * 10 = 500 이고 최대 500 * 5 = 2500 이다.
2단계: 개략적 설계안
API 설계, 개략적 아키텍처 및 데이터 모델에 대해 알아보자.
1) API 설계
POST /v1/scores
- 사용자가 게임에서 승리하면 순위표에서 사용자의 순위를 갱신한다.
- 클라이언트는 해당 API를 통하지 않고 순위표 점수를 직접 업데이트할 수 없다.
요청:
| 필드 | 설명 |
| user_id | 게임에서 승리한 사용자 |
| points | 사용자가 게임에서 승리하여 획득한 포인트수 |
응답:
| 이름 | 설명 |
| 200 OK | 사용자의 점수를 성공적으로 갱신한 경우 |
| 400 Bad Request | 잘못된 인자가 전달되어 사용자 점수를 갱신할 수 없었던 경우 |
GET /v1/scores
- 순위표에서 상위 10명의 플레이어를 가져온다.
GET /v1/scores/{:user_id}
- 특정 사용자의 순위를 가져온다.
| 필드 | 설명 |
| user_id | 순위 정보를 가져올 사용자 ID |
2) 개략적 설계안

- 사용자가 게임에서 승리하면 클라이언트는 게임 서비스에 요청을 보낸다.
- 게임 서비스는 해당 승리가 정당하고 유효한 것인지 확인한 다음 순위표 서비스에 점수 갱신 요청을 보낸다.
- 순위표 서비스는 순위표 저장소에 기록된 해당 사용자의 점수를 갱신한다.
- 해당 사용자의 클라이언트는 순위표 서비스에 직접 요청하여 데이터를 가져온다.
- 상위 10명 순위표
- 해당 사용자 순위
다른 대안을 어떤 잉유로 채택 안했는지 아래 질문을 살펴본다.
클라이언트가 순위표 서비스와 직접 통신해야 하나?
- 해당 방식은 사용자가 프락시를 설치하고 점수를 마음대로 바꾸는 중간자 공격을 할 수 있기 때문에 보안상 안전하지 않다는 문제가 있다.
- 점수는 서버가 설정해야 한다.
- 게임 서버가 모든 게임 로직을 처리하고, 게임이 언제 끝나는지 알기 때문에 클라이언트의 개입 없이도 점수를 정할 수 있다.
게임 서비스와 순위표 서버 사이에 메세지 큐가 필요한가?
- 게임 점수가 어떻게 사용되는지에 따라 크게 달라진다.
- 예를 들어, 순위표 서비스, 분석 서비스, 푸시 알림 서비스 등 여러 소비자가 동일한 데이터를 사용할 수 있으면 사용하는 것이 좋다.
- 본 설계안에서는 메세지 큐를 포함하지 않는다.
3) 데이터 모델
- 순위표 저장소는 본 시스템의 핵심 구성 요소 중 하나이다.
- 세 가지 기술, 관계형 데이터베이스 / 레디스 / NoSQL 을 살펴본다.
3.1. 관계형 데이터베이스
- 규모 확장성이 중요하지 않고 사용자 수가 많지 않다면 관계형 데이터베이스 시스템을 이용할 가능성이 높다.
- 각 월별 순위표는 사용자 ID와 점수열을 갖는 데이터베이스 테이블로 표현할 수 있다.
- 경연에서 승리하면 신규 사용자에게는 1점을 주고, 기존 사용자에게는 1점을 더한다.

사용자가 점수를 딴 경우:
- 레코드가 없는 사용자가 이긴 경우
INSERT INTO leaderboard (user_id, score) VALUES ('mary1934', 1);
- 이미 레코드가 있는 사용자의 점수 갱신
UPDATE leaderboard set score=score + 1 where user_id='mary1934'
특정 사용자 순위 검색:
- 순위표 테이블을 점수 기준으로 정렬한 다음에 순위를 매긴다.
SELECT (@rownum := @rownum + 1) AS rank, user_id, score
FROM leaderboard
ORDER BY score DESC;
데이터가 많지 않을 때는 효과적이지만, 레코드가 수백만 개 정도로 많이지면 성능이 너무 나빠지는 문제가 있다.
- SQL 데이터베이스는 지속적으로 변화하는 대량의 정보를 신속하게 처리하지 못한다.
- 다량의 일기 부하를 처리하기 어렵고 실시간 순위를 보여주어야 하는 요구사항에 적합하지 않다.
- 한 가지 방법으로 색인(INDEX)를 추가하고 LIMIT 절을 사용하여 스캔할 페이지 수를 제한할 수 있다.
- 하지만, 규모 확장성이 좋지 않고, 전체 테이블을 훑어야 하므로 성능이 떨어진다.
- 순위표 상단에 있지 않은 사용자의 순위를 간단히 찾을 수 없다.
3.2. 레디스
- 메모리에서 동작하므로 빠른 읽기 및 쓰기가 가능하다.
- 순위표 시스템 설계 문제를 해결하는 데 이상적인 정렬 집합이라는 자료형을 제공한다.
정렬 집합이란?
- 집합과 유사한 자료형으로 정렬 집합에 저장된 각 원소는 점수에 연결되어 있으며, 원소는 고유해야 하지만 같은 점수는 있을 수 있다.
- 내부적으로 해시 테이블과 스킵 리스트 라는 두 가지 자료 구조를 사용한다.
- 해시 테이블은 사용자의 점수를 저장
- 스킵 리스트는 특정 점수를 딴 사용자들의 목록을 저장
레디스 정렬 집합을 사용한 구현
- ZADD
- ZINCRBY
- ZRANGE/ZREVRANGE:
- ZRANK/ZREVRANK:
정렬 집합을 사용한 구현의 동작 원리
- 사용자가 점수를 획득한 경우
- ZINCRBY leaderboard_feb_2021 1 'mary1934'
- 사용자가 순위표 상위 10명을 조회하는 경우
- ZREVRANGE leaderboard_feb_2020 0 9 WITHSCORES
- 사용자가 자기 순위를 조회하는 경우
- ZREVRANK leaderboard_feb_2021 'mary1934''
- 특정 사용자 순위를 기준으로 일정 범위 내 사용자를 질의하는 경우
- ZREVRANGE leaderboard_feb_2021 357 365
3.3. 저장소 요구사항
- 레디스
- ID가 24자(charaacter) 문자열이고 점수가 16비트 정수라고 한다면 순위표 한 한목당 26바이트가 필요하다.
- 최악의 시나리오를 가정하면 26바이트 * 2,500만 = 6억 5,00만 바이트 또는 약 650MB의 저장공간이 필요
- 오버헤드와 정렬 집합 해시를 고려해 메모리 사용량을 두 배 늘린다고 해도 최신 레디스 서버 한대만으로도 데이터를 충분히 저장할 수 있다.
- 레드스 노드에도 장애가 발생할 수 있기 때문에 데이터의 영속성이 문제이다.
- 보통은 레디스에 일기 사본을 구성하여, 주 서버에 장애가 생기면 읽기 사본을 승격시켜 주 서버로 만들어준다.
- 관계형 데이터베이스
- 2개의 테이블이 필요
- 사용자 ID와 사용자의 게임 내 이름을 저장한다.
- 점수 테이블에는 사용자 ID, 점수, 게임에서 승리한 시각을 저장한다.
- 쉬운 성능 최적화 방안은 자주 검색되는 상위 10명의 사용자 정보를 캐시하는 것이다.
- 2개의 테이블이 필요
3단계: 상세 설계
1) 클라우드 서비스 사용 여부
솔루션 배포 방식은 기존 인프라 구성 형태에 따라 일반적으로 두 가지로 나눌 수 있다.
자체 서비스를 이용하는 방안
- 매월 정렬 집합을 생성하여 해당 기간의 순위표를 저장한다.
- 해당 집합에는 사용자 및 점수 정보를 저장한다.
- 이름 및 프로필 이미지와 같은 사용자 세부 정보는 MySQL 데이버테이스에 저장한다.
- 순위표를 가져 올 때 API 서버는 순위 데이터와 더불어 데이터베이스에 저장된 사용자 이름과 프로필 이미지를 가져온다.

클라우드 서비스를 이용하는 방안
- 아마존 API 게이트웨이와 AWS 람다 두 가지 기술을 사용한다.
- AWS 람다는 인기 있는 서버리스 컴퓨팅 플랫폼 중 하나이다.
- 필요할 때만 실행되며 트래픽에 따라 그 규모가 자동으로 확장된다.
- 게임은 API 게이트웨이를 호출하고, 게이트웨이는 적절한 람다 함수를 호출한다.
사례 1: 점수 획득

사례 2: 순위 검색

2) 레디스 규모 확장
최악의 경우를 생각하여 샤딩이 필요하다.
2.1 데이터 샤딩 방안
- 고정 파티션과 해시 파티션 두 가지 방식을 살펴보자.
고정 파티션
- 순위표에 등장하는 점수의 범위에 따라 파티션을 나누는 방안이다.
- 예를 들어 획득할 수 있는 점수 범위가 1에서 1000이라고 한다.
- 샤드를 10개 두면, 각 샤드가 크기 100만큼의 범위를 처리한다.
(1~100, 101~200, 201~300, ...)
- 각 샤드에 할당되는 점수 버위를 조정하여 비교적 고른 분포가 되도록 해야 한다.
- 특정 사용자의 점수를 입력하거나 갱신할 때 해당 사용자가 어느 샤드에 있는지 알아야 한다.
- MySQL 질의를 통해 사용자의 현재 점수를 계산하여 알아내는 것도 한 가지 방안이다.
- 하지만, 사용자 ID와 점수 사이의 관계를 저장하는 2차 캐시를 통해 알아내면 성능을 더 높일 수 있다.
- 사용자의 점수가 높아져서 다른 샤드로 옮겨야 할 때 기존 샤드에 해당하는 사용자를 제거한 다음에 새 샤드로 옮겨야 한다.
해시 파티션
- 레디스 클러스터를 사용하는 것으로, 사용자들의 점수가 특정 대역에 과도하게 모여 있는 경우에 효과적이다.
- 레디스 클러스터는 여러 노드에 데이터를 자동으로 샤딩하는 방법을 제공한다.
- 안정 해시는 사용하지 않지만, 각각의 키가 특정한 해시 슬롯에 속하도록 하는 샤딩 기법을 사용한다.
- 따라서, 모든 키를 재분배하지 않아도 클러스터에 쉽게 노드를 추가하거나 제거할 수 있다.
- CRC16(key) % 16348의 연산을 수행하여 어떤 키가 어느 슬롯에 속하는지 계산한다.
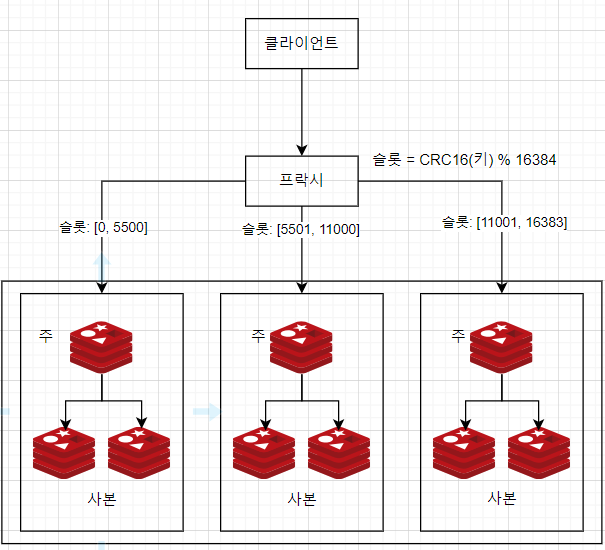
- 상위 10명의 플레이어를 검색하는 것은 좀 까다롭다.
- 모든 샤드에서 상위 10명을 받아 애플리케이션 내에서 다시 정렬하는 분산-수집 접근법을 사용해야 한다.
- 모든 샤드에 사용자를 질의하는 절차를 병렬화하면 지연 시간을 줄일 수 있다.
문제점
- 상위 K개의 결과를 반환해야 하는 경우, 각 샤드에서 많은 데이터를 읽고 또 정렬해야 하므로 지연 시간이 늘어난다.
- 가장 느린 파티션에서 데이터를 다 읽고 나서야 질의 결과를 계산할 수 있으므로 지연 시간이 길어진다.
- 특정 사용자의 순위를 결정할 간단한 방법이 없다.
레디스 노드 크기 조정
- 쓰기 작업이 많은 애플리케이션에는 많은 메모리가 필요하다.
- 장애에 대비해 스냅숏을 생성할 때 필요한 모든 쓰기 연산을 감당할 수 있어야하기 떄문이다.
- 쓰기 연산이 많은 애플리케이션에는 메모리를 두 배 더 할당하는 것이 안전하다.
- 레디스는 성능 벤치마킹을 위해 redis-benchmark라는 도구를 제공한다.
- 여러 클라이언트가 동시에 여러 질의를 실행하는 것을 시뮬레이션하여 주어진 하드웨어로 초당 얼마나 많은 요청을 처리할 수 있는지 측정한다.
3) 대안: NoSQL
다음과 같은 데이터베이스가 이상적이다.
- 쓰기 연산에 최적화되어 있다.
- 같은 파티션 내의 항목을 점수에 따라 효율적으로 정렬이 가능하다.
후보로는 아마존의 DynamoDB, 카산드라 또는 MongoDB 등이 있다.
- DynamoDB는 안정적인 성능과 뛰어난 확장성을 제공하는 완전 관리형 NoSQL데이터베이스이다.
- 기본 키 이외의 속성을 활용하여 데이터를 효과적으로 질의할 수 있도록, 전역 보조 색인을 제공한다.
순위표와 사용자 테이블을 비정규화 한다.
- 해당 방안은 규모 확장이 어렵다.
- 레코드가 많아지면 상위 점수를 찾기 위해 전체 테이블을 뒤져야 하므로 사용자가 많아지면 성능이 덜어진다.
| 기본키 | 속성 | |||
| user_id | score | profile_pic | leaderboard_name | |
game_name#{year-month}을 파티션키로, 점수를 정렬키로 사용하면 테이블 전체를 읽어야 하는 일을 피할 수 있다.
- 해당 테이블은 최근 한 달치 데이터가 동일한 파티션에 저장되고 핫 파티션이 되는 문제가 있다.
- 해결 방법 첫 번째로 데이터를 n개 파티션으로 분할하고 파티션 번호를 파티션 키에 추가하는 것이다.
- 쓰기 샤딩이라고 부르는 패턴이지만, 읽기 및 쓰기 작업 모두를 복잡하게 만드므로 장단점을 꼼꼼히 따져야 한다.
- 두 번째는 얼마나 많은 파티션을 두는 것이다.
- 같은 달 데이터를 여러 파티션에 고르게 분산시키면 한 파티션이 받는 부하는 낮아진다.
- 하지만, 특정한 달의 데이터를 읽으려고 하면 모든 파티션을 질의한 결과를 합쳐야 하므로 구현은 훨씬 복잡하다.
| 전역 보조 색인 | 속성 | |||
| 파티션 키 | 정렬 키 | user_id | profile_pic | |
game_name#{year-month}#p{partition_number}를 파티션 키로, 점수를 정렬 키로 사용하게 구성한다.
- n개의 파티션이 만들어진다.
- 상위 10명의 사용자를 가져오려면 '분산-수집' 접근법을 사용하면 된다.
4단계: 마무리
1) 더 빠른 조회 및 동점자 순위 판정 방안
레디스 해시를 사용하면 문자열 필드와 값 사이의 대응 관계를 저장해 둘 수 있다.
- 순위표에 표시할 사용자 ID와 사용자 객체 사이의 대응관계를 저장한다
- 데이터베이스에 질의하지 않아도 빠르게 사용자 정보를 확인할 수 있다.
- 두 사용자의 점수가 같은 경우 누가 먼저 점수를 받았는지에 따라 순위를 매길 수 있다.
- 사용자 ID와 해당 사용자가 마지막으로 승리한 경기의 타임 스탬프 사이의 대응관계를 저장해 두는 것이다.
2) 시스템 장애 복구
레디스 클러스터도 장애가 발생할 수 있다.
- 사용자가 게임에서 이길 때마다 MySQL 데이터베이스에 타임스탬프와 함께 사실을 기록한다는 사실을 활용하는 스크립트를 만들면 간단히 복구할 수 있다.
- 사용자별로 모든 레코드를 훑으면서, 레코드당 한 번씩 ZINCRBY를 호출하는 것이다.
'읽은 책 > [책] 가상 면접 사례로 배우는 대규모 시스템 설계 기초 2권' 카테고리의 다른 글
| 9장. S3와 유사한 객체 저장소 (0) | 2024.08.28 |
|---|---|
| 11장. 결제 시스템 (0) | 2024.08.25 |
| 8장. 분산 이메일 서비스 (0) | 2024.08.21 |
| 7장. 호텔 예약 시스템 (0) | 2024.08.18 |
| 6장. 광고 클릭 이벤트 집계 (1) | 2024.08.15 |